Contexte
Une mode en cours sur le web consiste à intégrer dans les pages web des ressources externes tierces (Google Analytics, Google Fonts, Facebook, Twitter…). Malheureusement, ces inclusions sont autant de traceurs qui collectent des données personnelles sur les webonautes. Le pire, c’est que ces acteurs tiers :
- n’offrent aucune information sur ce qu’ils font des données collectées ;
- ne garantissent en rien que les données collectées seront protégées efficacement ;
- sont soumis à des lois pouvant porter atteinte aux citoyens européens (Patriot Act…).
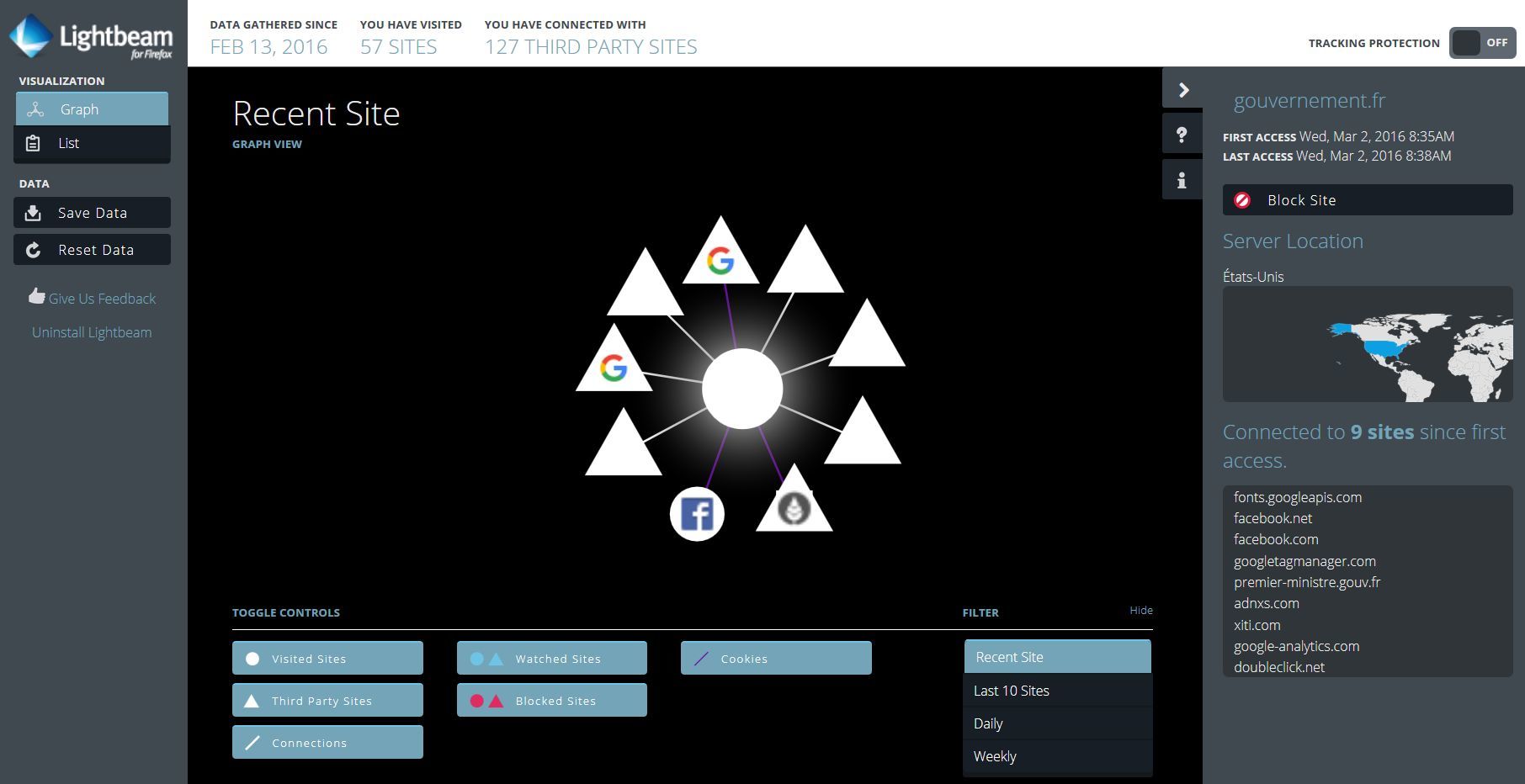
Une méthode pour constater ces traceurs indélicat : dans Firefox, installer le plugin ResquestPolicy (logiciel libre).
Le problème
Certains sites étatiques sont orientés « politique », « emploi » ou « santé ». Voir ces sites se rendre complices du traçage des citoyens et ne pas garantir ce qui est fait avec leur données personnelles, cela est très inquiétant.
Quelques exemples :
- le site web de Pôle emploi (http://www.pole-emploi.fr/) : XITI ;
- le site web du gouvernement (http://www.gouvernement.fr/) : Google Fonts, XITI, Twitter ;
- le site de l’Assemblée nationale : Google Analytics, Facebook ;
- le site de l’Assurance maladie (http://www.ameli.fr/) : DoubleClick, XITI ;
- le blog d’Etalab (http://www.etalab.gouv.fr/) : Google API, WP, Flickr ;
- etc.
Solution
Puisqu’il est impossible de garantir ce que font les fournisseurs tiers de services, il convient de ne pas les utiliser. Les sites de l’État et des organismes publics doivent bannir de leurs pages ces traceurs.
Pour la collecte de statistiques d’utilisation du site web, des solutions hébergées en interne sont disponibles (http://fr.piwik.org/).
Un contre-exemple exemplaire est le forum d’Etalab qui ne contient aucun traceur externe mais un traceur interne dont les données sont correctement gérées sur un serveur d’Etalab.
Proposition
Pour régler ce crucial problème de sécurité des données personnelles et d’intimité numérique, il est souhaitable que une directive venant du plus haut niveau impose le bannissement de toute solution de traçage externe dans les sites web étatiques et des organismes publics.